پیچیدگی کپچا بی فایده است
اثبات انسان بودن در دنیای دیجیتال کنونی، سختتر از همیشه شده است

پیچیدگی کپچا حالا به عاصی شدن همه ما منجر شده است.
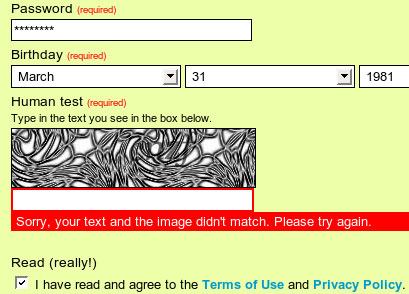
سال گذشته آزمون تفکیک انسان از رایانه یا به اصطلاح کپچا به شکل وسیع و سختگیرانهای در سایتهای اینترنتی به کار گرفته شد.
کپچاها که زمانی آزمون های کوچک، ساده و بانمک اینترنتی بودند، حالا بسیار سخت گیرانه و پیچیده شدهاند.
آنها برای اینکه ثابت کنند شما انسان هستید مرتبا شیوههای سختگیرانهتری را به اجرا میگذارند.
در واقع میتوان گفت طی سالهای اخیر پیچیدگی کپچا مرتبا بیشتر و بیشتر شده است.
این تستهای کوچک اینترنتی، اصطلاحا کپچا یا CAPTCHA نام دارند که مخفف « Completely Automated Public Turing test » یا «آزمون همگانی کاملاً خودکارشدهٔ تورینگ برای مجزا کردن انسان و رایانه» است.
در اوایل دهه 2000، تصاویر ساده به همراه نوشتهای کوچک برای تشخیص کاربر انسان و ربات کافی بود ولی حالا با گذشت یک دهه، سیستم کچپاها بسیار پیشرفتهتر، حرفهای تر و سختتر شده و سوالات چالش برانگیزی در برابر کاربر قرار میگیرد.
پیچیدگی کپچا وضعیت متناقضی برای همه ما ایجاد کرده است.
شکی نیست که با پیشرفت تکنولوژیهایی مانند یادگیری ماشینی و هوش مصنوعی، حالا پروسههای تفریق انسان از ربات باید سختتر شود.
در سال 2014، گوگل یک سیستم الگوریتم یادگیری ماشینی را در برابر یک کامپیوتر و یک انسان قرار داده و هر دو سعی کردند که یک تست کپچای بسیار پیچیده را هم زمان حل کنند.
نتیجه این تست این شد که کامپیوتر در 99.8 درصد موارد توانست به گزینه درست اشاره کرده و انسان تنها 33 درصد سوالات را به درستی جواب داد!
بعد از این بود که گوگل سیستم خود را به NoCaptcha ReCaptcha تغییر داد.
مرتبط: گوگل کپچا را کنار میگذارد
در سیستم جدید، گاهی اوقات نرم افزار گوگل با بررسی اطلاعات و فعالیتها، به برخی از کاربران انسان با تیک زدن گزینه «من ربات نیستم» اجازه عبور داده و برخی مواقع نیز تصاویر کپچا برای وی به نمایش در میآید. اما آیا ماشین ها این بار نیز به انسانها میرسند؟
چالش اثبات انسان بودن در عصر ماشینها

Jason Polakis، پرفسور علوم کامپیوتری در دانشگاه ایلینویز در شیکاگو سختتر شدن کپچاها را منطقی میداند.
در سال 2016، وی مقالهای به چاپ رساند که در آن توضیح داده چگونه با استفاده از ابزارهای تشخیص تصویر، از جمله تکنولوژی خود گوگل، توانسته تصاویر کپچاها را 70 درصد با موفقیت شناسایی کند.
محققان دیگری نیز با استفاده ابزار نرم افزاری تشخیص دهنده صوتی خود گوگل، موفق شدهاند کپچاهای صوتی این شرکت را به راحتی حل کنند.
به گفته Polakis، تکنولوژی یادگیری ماشینی این روزها به اندازه انسانها در مواردی همچون تشخیص تصویر و تشخیص صدا، حرفهای است.بنابراین پیچیدگی کپچا کمکی به انسان نمیکند.
در واقع، الگوریتمهای کامپیوتری در بیشتر موارد حتی بهتر از انسانها نیز عمل میکنند:« ما به نقطهای رسیدیم که ارائه موانع سخت برای دسترسی رباتها، به موانع سختتری برای انسان ها تبدیل میشود. ما باید به دنبال روش جایگزینی باشیم که فعلا هیچ ایدهای در اینباره نداریم.»
پروفسور پولاکیس : ما به نقطهای رسیدیم که ارائه موانع سخت برای دسترسی رباتها، به موانع سختتری برای انسان ها تبدیل میشود.
محققان، دسته بندیهایی همچون ارائه تصایر و اصوات تفکیک شده بر اساس نژاد، جنسیت، موقعیت فرهنگی و جغرافیایی و چند حوزه دیگر که کامپیوترها فعلا به آنها زیاد احاطه ندارند را فعلا به عنوان راه حل جازگزین در حال بررسی دارند.
اخیرا روش جدیدی در حال آزمایش است که در آن از کپچاهای بازی مانند-گیمینگ- استفاده میشود، تستهایی که کاربران باید با توجه به دستورالعملهای نوشتاری ارائه شده، در آن اشیا را جابهجا کرده و در زوایای به خصوص قرار دهند و یا پازلها را به درستی حل کنند.
تمامی این شیوهها به این امید طراحی شده که منطق انسانها، آنها را نسبت به ماشینها جلو بیندازد.
محققان دیگری نیز هستند که معتقدند باید با استفاده از دوربینهای دستگاه، سندی برای ثبات حقیقی بودن کاربران ارائه شود.
تمام روشهای جدید، یک مشکل کلی دارند: رباتها لزوما باهوشتر از انسانها نیستند بلکه این کاربران انسانی هستند که معمولا در تستهای ارائه شده افتضاح به بار میآورند! و دلیل آنهم، کم هوشتر بودن انسانها نیست بلکه تفاوتهای زبانی، فرهنگی و تجربه است که باعث بالا بردن درصد خطا و اشتباه در جواب کاربران انسان میشود
. محققان باید به دنبال راه حلی باشند که برای عموم مردم آسان است، حوزهای که کامپیوترها و ماشینها روی آنها احاطهای ندارند.
همین مسئله، گزینهها را بسیار محدود میکند. اما بالاخره باید حوزهای باشد که انسانها در آن بهتر هستند.
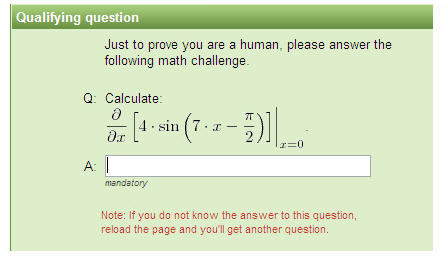
پیچیدگی کپچا و سوال های بیجواب؟
اما واقعا چه جنبهای از قابلیتهای انسانی میتواند نسبت به تکنولوژیهای پیشرفته ماشینها برتری پیدا کند؟
انسان بودن حقیقتا چه مزیتی دارد؟ این سوالات که به ذهن خطور میکند، مسئله را به مرزهای فلسفی و اخلاقی وارد میکند و دسترسی به جواب را سختتر. اینکه آیا انسان بودن صرفا با تکیه بر قابلیتهایش قابل سنجش است؟
Shuman Ghosemajumder یکی از کارمندان اسبق بخش امینیت سایبری گوگل است.
وی در مورد پیچیدگی کپچا معتقد است که تمام موانع موجود از کچاهای ویدیویی، کارتونی، صوتی و غیره بالاخره توسط ماشینها قابل رسوخ است:« باید نوعی تایید هویتی برای کاربران انجام شود.
باید فعالیتها و رفتارهای کاربر به دقت بررسی شده و تحت نظارت قرار بگیرد و هرگونه رفتار ماشین محور، شناسایی شود. مثلا یک کاربر انسان، حرکات زیاد موس روی صفحه نمایش انجام میدهد ولی ماشین بدون خطا، تنها به سراغ هدف مورد نظر خود میروند.»
تیم کپچای گوگل نیز در حال تحقیق به روی همین مسئله هستند.
با رشد تکنولوژی ماشینی، تستها نیز سخت و سختتر میشود ولی چاره ای نیست. مدیر تیم کپچای گوگل
آخرین نسخه نرم افزار جدید reCaptch v3 ، سال گذشته معرفی شد که با استفاده از تکنیک «تجزیه و تحلیل سازگاری خطرها»- adaptive risk analysis- میتواند فعالیتهای مشکوک ترافیک کاربران را شناسایی کرده و کاربران مشکوک، با چالشهای بیشتر روبرو میشوند.
این تکنیک البته نقطه ضعفهای مخصوص به خود را دارد.
Aaron Malenfant، مدیر بخش مهندسی تیم کپچای گوگل میگوید که در این رقابت، انسانها نباید بازنده شوند:« با رشد فزاینده تکنولوژی ماشینی، تستهای تایید برای کاربر انسان نیز سخت و سختتر میشود ولی چاره ای نیست.
CAPTCHA V3 هم با همین هدف معرفی شده است اما درصد بالای خطا و اشتباه در انسانها، کار را سخت میکند.» در واقع پیچیدگی کپچا کمکی به ما نکرده است.
Malenfant معتقد است که 5 تا 10 سال آینده، سیستم چالشهای کپچا به احتمال زیاد عملا بی کاربرد خواهد بود و وب سایتها نیز باید مدام از تورینگهای امنیتی مخفیانه برای کنترل ترافیک خود استفاده کنند تا راه حل کاربردی برای معضل پیدا شود.



