هنگامی که صحبت از اسید deoxyribonucleic یا همان DNA (به عنوان مولکولی که حامل اطلاعات ژنتیکی است) میشود، محققان معمولا مشابهتهایی میان سیستمهای رایانهای و DNA، به عنوان برنامهای گسترده که توسط سختافزار بدن اجرا میشود را لحاظ میکنند. با این وجود تفاوتهای آشکاری میان کدهای ژنتیکی DNA و کدهای باینری مورد استفاده توسط رایانهها وجود دارند و هریک نیز مزایا و محدودیتهای خاص خود را دارند. در ادامه به برخی از این تفاوتها اشاره خواهیم کرد.
شمارش ارقام
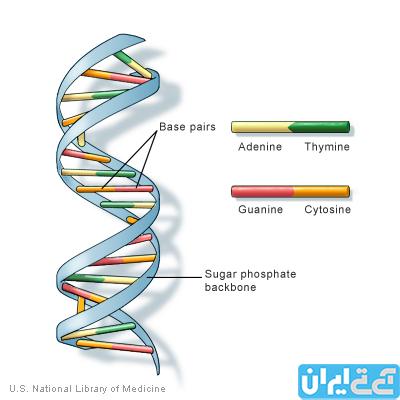
سادهترین واحد کد باینری، رقم دودویی یا همان “بیت” است که میتواند دو مقدار 0 یا 1 را به خود اختصاص دهد. در سمت مقابل، سادهترین واحد DNA نیوکلئوتاید است که میتواند چهار داده اساسی یعنی آدنین، سیتوزین، تیمین یا گوانین (A,C,T,G) را در خود جای دهد. این در حالی است که تنها ترکیبهای A+T و C+G میتوانند جفتهای پایهای را تشکیل دهند. یک توالی پیوسته از DNA، یک کروموزوم را تشکیل میدهد. این تنوع حکایت از آن دارد که هر نیوکلئوتاید DNA میتواند اطلاعاتی دوبرابر بیشتر از هر رقم یک برنامه دودویی یا همان باینری را در خود جای دهد. انسانها 46 کروموزوم در قالب 23 جفت در اکثر سلولهای خود دارند.
اندازه بایت
سیستمهای رایانهای و زیستی، هر دو کدهای مربوطه را در قالب بلوکهایی از چندین واحد میخوانند و از روش تحلیل هر بیت یا نوکلئوتاید بهصورت مستقل از یکدیگر، استفاده نمیشود. اطلاعات باینری در قالب مجموع هشت بیت، یک بایت را تشکیل میدهند و هر بایت یک ترکیب از 256 ترکیب ممکن از صفرها و یکها را خواهد داشت. در مقام مقایسه، اطلاعات ژنتیکی در قالب سهگانههای نیوکلئوتایدی که از آنها با عنوان کدون یاد میشود قرار میگیرند که آمینو اسیدهای متفاوتی را ارائه میدهند. این بدانمعناست که هر بایت DNA، تنها 64 حالت ممکن خواهد داشت.
شروع و توقف
هم کدهای باینری و هم کدهای ژنتیکی حاوی سیگنالهایی هستند که مکان شروع و پایان خواندن پیامهایشان را مشخص میکنند. رایانهها از بیتهای شروع و پایان بدین منظور بهره میبرند و کدهای ژنتیکی از یک کدنِ شروع و سه کدنِ توقف بهرهمند شدهاند. با این وجود، DNA معمولا از انعطافپذیری بهمراتب بالاتری در شروع و توقف بهرهمند شده و قسمتهای مشخصی از کدهای ژنتیکی را میتوان در بخشهای متفاوت و همراه با همپوشانی، خواند.
حفاظت از دادهها
در کدهای دیجیتالی، یک بیت ناصحیح میتواند به ایجاد مقداری متفاوت برای آن بایت منجر شود و نهایتا مشکلاتی قابل توجه را در برنامه رایانهای رقم خواهد زد. DNA در این زمینه انعطافپذیری بیشتری داشته و اکثر تغییرات نیوکلئوتایدها منجر به تغییر ارزش و مقادیر در نظرگرفته شده برای آمینو اسید کدنویسیشده توسط کدن، نخواهند شد. اگرچه 64 کدن مختلف در دسترس قرارگرفته اما فرایندهای بیولوژیکی تنها از 20 آمینو اسید در ساخت پروتئینها بهره میبرند این در حالی است که اکثر کدنهایی که به واسطه تفاوت یک نیوکلئوتاید از دیگری متمایز هستند، از آمینو اسید مشابهی بهره میبرند. از این قابلیت با عنوان افزونگی یا Redundancy یاد میشود که اطلاعات ژنتیکی را در برابر خطاهای اجتناب ناپذیری که در همانند سازی و خواندن DNA ایجاد میشوند، محافظت میکند.
منبع : آی تی ایران



